Working with R packages
r_packages.RmdAim of the Game
Have you ever been in that situation where your R script is painfully long? Something like:
# first remove everything on the environment
rm(list = ls())
# then install the packages you need
install.packages("ggplot2")
install.packages("nlmer")
install.packages("rethinking")
install.packages("whatever")
install.packages("some bullshit I need 4 just that one line")
# then load the packages
library(ggplot2)
library(nlmer)
library(rethinking)
library(whatever)
library(some bullshit I need 4 just that one line)
# then load the data
data <- read.csv(C:/was_it_this_folder?/within_this_one?/not_sure/maybe_here?/data.csv)
# then tidy the raw data and only keep what you need for your analysis
actual_data <- data.frame(unicorn_id = data$UniCorn_Identity,
horn_length = data$Length_of_THe_horn_of_the_UNicorn,
weight = data$W_of_the_Unicorn_when_born)
# to then finally be able to run the fricking analysis
model <- lm(horn_length ~ weight, actual_data)
# to then get a fricking ERROR AGAIN GODDAMN IT! Installing packages, loading them, cleaning data, preparing it for analysis, doing the analysis and plotting the results all within the same file can result in absurdly long R scripts. There is a way to solve this and it is by treating your entire research project as an R package. Let me explain:
What is an R package?
An R package is a type of R project, in other words, a way to work with R on a specific topic. A package, just like any project, is set up from a folder in your computer that you set up where you store all your files and data. If you develop your own R package it will work similarly to those packages you install and load every time you run an R script (i.e ggplot2, nlmer etc.) when you need a function that does something useful, only this time, you will be the person behind the scenes!
A package can include, functions, data, and all kinds of scripts to process or document your work. As an example, I have developed the package cataract por the EcoLunch presentation. I can load this package and with it I can specify other packages that need to be both installed and loaded with it with the function
devtools::load_all()When loading the package I can also access functions that I have written myself to perform specific tasks. For example, here is a function that generates facts about Chris H. with different degrees (1-5) of spicyness:
generate_chris_fact(spicyness = 3)## [1] "Chris has an awesome mustache"
I can also access any data sets I am working with. I can actually save them after being processed and with the variables I want so when I load them they are ready to be played with. As an example, I have added some avengers data to the cataract project:
# just typing the dataset's name when the package is loaded will make the data pop up!
avengers## name intelligence power
## 1 black panther 88 66
## 2 black widow 75 32
## 3 captain america 63 65
## 4 captain marvel 80 95
## 5 doctor strange 95 84
## 6 falcon 63 30
## 7 groot 6 75
## 8 hawkeye 70 35
## 9 hulk 10 94
## 10 iron man 99 67
## 11 scarlett witch 96 100
## 12 vision 100 96
## 13 winter soldier 55 64
## 14 thor 60 90And this is just the tip of the iceberg of the things you can do with your R package! Would you be interested in creating one for yourself? Here are some tips:
Creating your own R package
Okay dude but how in the hell do you actually do this? No problem! Here is a step by step tutorial for you:
Step 1
Have you ever noticed when you open Rstudio that little R sign that says something like Project:(None). Click there and go to New Project.
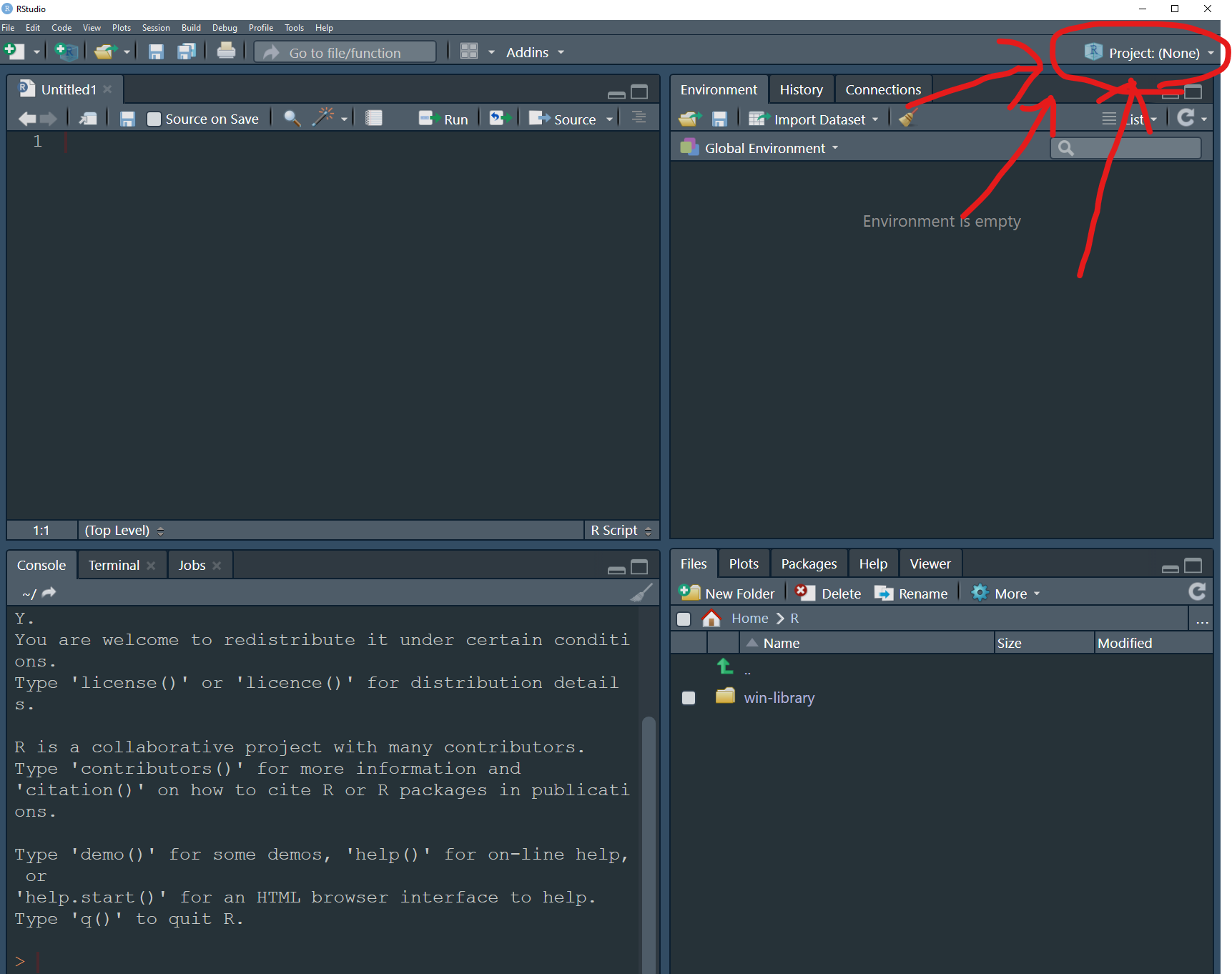
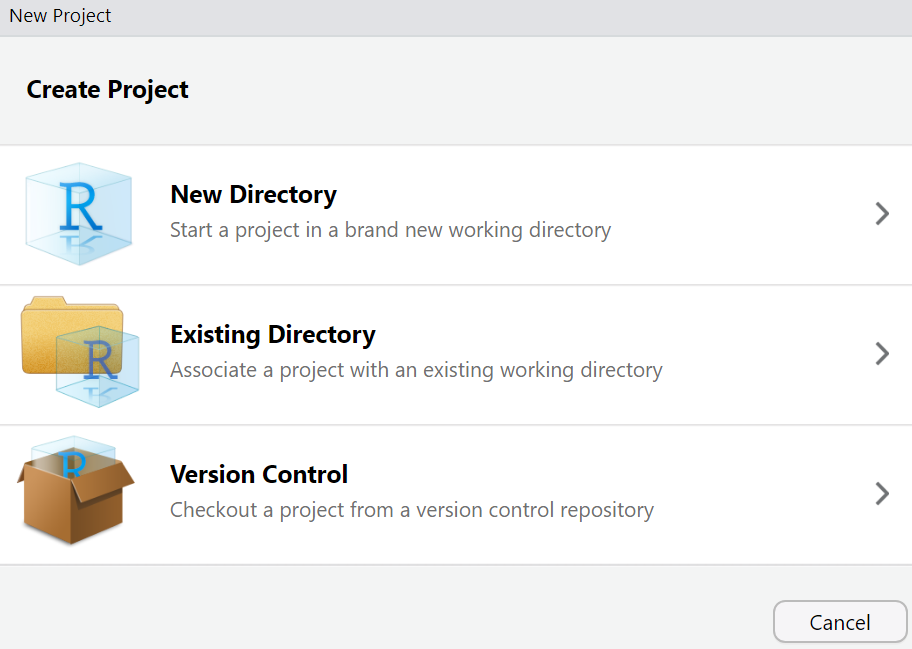
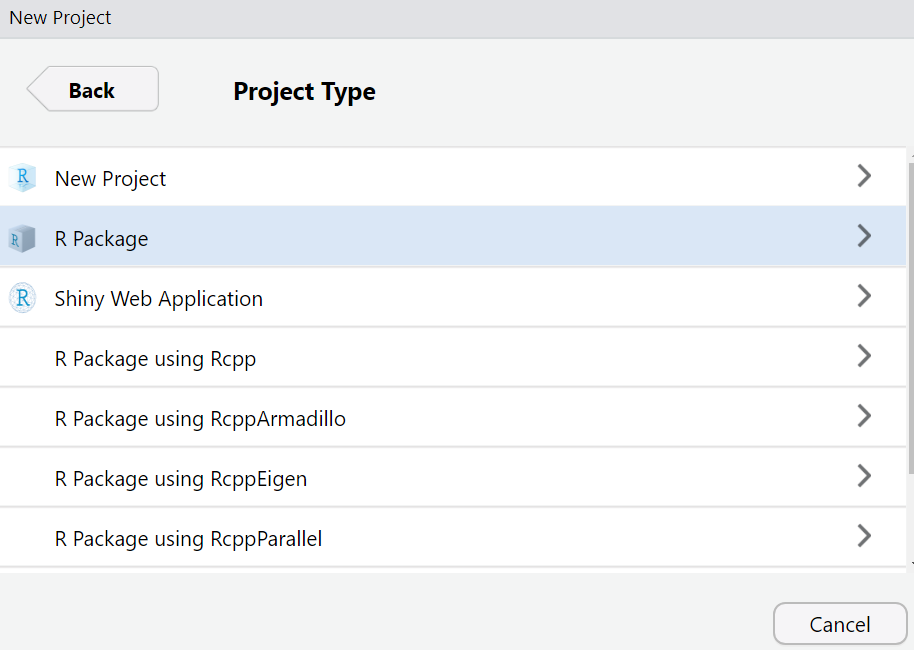
Step 4
Which will open this:
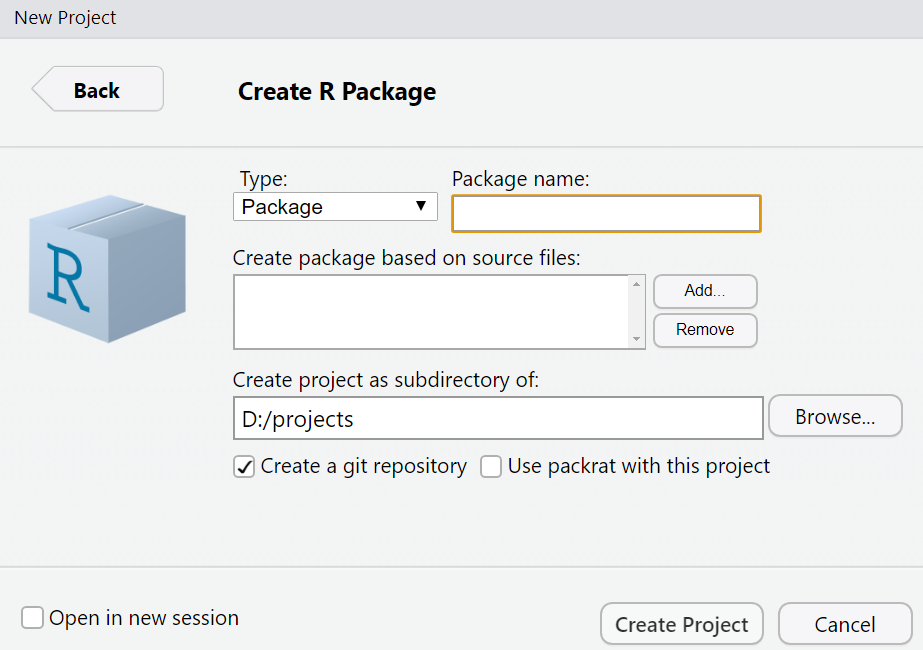
Three things to consider here:
- Name of your package: Package naming needs to meet certain formalities. In this link: https://r-pkgs.org/workflows101.html?q=namin#naming you will find them as well as some pragmatic advice on naming. My personal recommendation is to name your packages with a single word that is descriptive enough and that motivates you to work on it. What I do is name my packages using extremely geeky associations which are related with what the package is about in a funny way.
-
Make sure you create the folder for the package on a directory you know!: You can set it up on your Desktop, that’s fine! But remember it is there!. What I recommend, as kind of a technological tidiness nerd is to create a specialized folder for
projectswhere you can locate all your work!
-
Make sure you create the folder for the package on a directory you know!: You can set it up on your Desktop, that’s fine! But remember it is there!. What I recommend, as kind of a technological tidiness nerd is to create a specialized folder for
-
Don’t forget about
GIT! You should have GIT installed in your computer right now (if not go to: https://ggcostoya.github.io/cataract/articles/git.html and check how to do it). If you indeed have it, a little check box withCreate git repositoryshould appear in this screen. Be sure to check that box! It will be essential later.
-
Don’t forget about
Once you are done, click on Create Project and KABOOM! Congrats! You’ve created your first R package, now it’s time to see what is going on here.
Elements of your R package
As soon as you create your R package you will see that a bunch of folders automatically appear on the folder for it. You can see these in the lower right-hand panel in Rstudio where it says Files, it should look something like this:
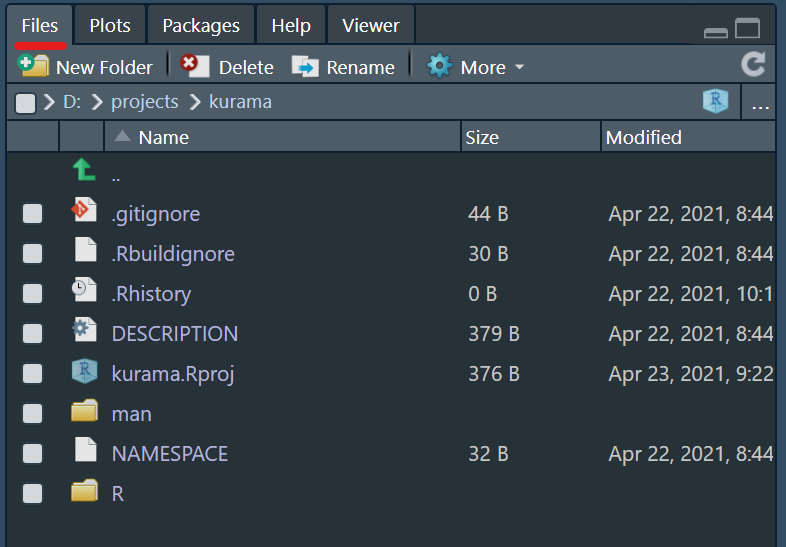
Among these files and documents the ones you got to pay attention to are:
.Rproj
The .Rproj file is the source to all of your R package. In this case, as an example, I’ve created the kurama package so in the picture above you see kurama.Rproj. When you create projects of your own the .Rproj file will be your package’s name. If you go to the folder where you created the package and click on it an R session with your package name will appear. Notice also that on the top right hand side it doesn’t say Project:(None) anymore! The name of your package should appear up there.
DESCRIPTION
The DESCRIPTION file contains all the information related to your project. If you open it, it should look like this:
Package: kurama # here's my example, but here the name of your package will appear.
Type: Package
Title: What the Package Does (Title Case)
Version: 0.1.0
Author: Who wrote it
Maintainer: The package maintainer <yourself@somewhere.net>
Description: More about what it does (maybe more than one line)
Use four spaces when indenting paragraphs within the Description.
License: What license is it under?
Encoding: UTF-8
LazyData: trueThe DESCRIPTION file can include all Dependencies, which are all packages that need to be installed and loaded for your package to run. You will need to add them manually. You can also add information about the package (title, author, description etc.). As an example, here is the DESCRIPTION file for cataract:
Package: cataract
Type: Package
Title: Project Cataract
Version: 1.0
Author: Guillermo Garcia Costoya
Maintainer: Guillermo Garcia Costoya <guille@nevada.unr.edu>
Description: A quick guide on how to use GIT, R packages, GitHub and GitHub pages
as part of your research process to keep your files and data tidy, tracked, organized
and kewl. A package develop to complement the April 30th 2021 EcoLunch talk by
Guillermo Garcia Costoya at the EECB program of the University of Nevada, Reno
License: What license is it under?
Encoding: UTF-8
LazyData: true
Depends: ## Here you will need to specify the packages you want to be installed and loaded!
R(>= 3.3.0),
tidyverse,
devtools,
DescTools,
gridExtra,
here
RoxygenNote: 7.1.1 ## Do me a favor and add this as well if you are copy pasting. It's for your own good. Setting up a DESCRIPTION file like this saves you the trouble of having to install and load packages every time. You just need to include them as Dependencies and BOOM! They will be loaded every time you load your R package!
\R
The \R folder will contain all the functions for your package. If you click there as soon as you create your package you’ll see that R has automatically created a function called hello, which is saved on the hello.R file that looks like this:
# Hello, world!
#
# This is an example function named 'hello'
# which prints 'Hello, world!'.
#
# You can learn more about package authoring with RStudio at:
#
# http://r-pkgs.had.co.nz/
#
# Some useful keyboard shortcuts for package authoring:
#
# Install Package: 'Ctrl + Shift + B'
# Check Package: 'Ctrl + Shift + E'
# Test Package: 'Ctrl + Shift + T'
hello <- function() {
print("Hello, world!")
}
The goal here is that you create functions for yourself to make tasks easier and more repeatable. Writing your own functions is a way to avoid repetitions and keep your code short. For example, let’s say that for the avengers data set I showed you earlier I want to determine who would win in a fight between Vision and Thor:
# let's check the data first once again:
avengers## name intelligence power
## 1 black panther 88 66
## 2 black widow 75 32
## 3 captain america 63 65
## 4 captain marvel 80 95
## 5 doctor strange 95 84
## 6 falcon 63 30
## 7 groot 6 75
## 8 hawkeye 70 35
## 9 hulk 10 94
## 10 iron man 99 67
## 11 scarlett witch 96 100
## 12 vision 100 96
## 13 winter soldier 55 64
## 14 thor 60 90
# filter the data to keep only data for vision and thor
avg_vision_thor <- filter(avengers, name %in% c("vision", "thor"))
# keep the avenger with the highest power value
winner <- filter(avg_vision_thor, power == max(power))
# extract the name of the winner
name_winner <- as.character(winner$name)
# and here's the winner! VISION! of course...
name_winner## [1] "vision"
# what if I needed to know who would win between scarlett witch and hulk?
# Redo the entire shannanigan again? HELL NO!
# I can write a function to automate this process. I can call this function "match_avengers":
match_avengers <- function(avg_1, avg_2){
# avg_1 and avg_2 are the arguments of the function,
# filter avenger data and keep only two specified avengers as well as the most powerful one
match <- avengers %>% filter(name %in% c(avg_1, avg_2)) %>% filter(power == max(power))
# get the name of the winner
winner <- as.character(match$name)
return(winner)
}
# let's test the function out! SCARLETT WITCH ALL DAY!!
match_avengers("scarlett witch", "hulk")## [1] "scarlett witch"
If you check the \R folder for the cataract package here: https://github.com/ggcostoya/cataract/tree/master/R , you’ll see that one of the files there is for the match_avengers function. If it is there I can use the function any time cataract is loaded!
Elements you NEED TO ADD to your R package
Although the package would work with the basic stuff that is generated when you created, to upgrade your R package to the next level you’ll need to create the following folders:
\raw_data
In the \raw_data folder you will save all data that comes fresh from the field or the lab. I am talking about those messy excels, .txt files, .csv files anything! All in there. The \raw_data folder will also contain what I call cleaning scripts. These will have all the data processing, filtering and cleaning necessary for your raw data to become the actual data you’ll use in your scripts.
If you go to: https://github.com/ggcostoya/cataract/tree/master/raw_data, you’ll be to see the raw data for the cataract. As an example I have included some meerkats data a friend of mine used for a project a couple of years ago. Below is an an example cleaning script (called meerkats_data_prep.R):
## Meerkat data preparation
library(here) # load here package
meerkats <- read.table(file.path(here(), "raw_data", "meerkats.txt")) # load the raw meerkat data
# rename some columns to make analysis easier
meerkats <- data.frame(obs_feeds = meerkats$observedNfeeds,
obs_hours = meerkats$observedhours,
r_2_brood = meerkats$relatedness2brood,
group_id = meerkats$socialgroupID,
brood_id = meerkats$broodID,
delta_mass = meerkats$massChange)
# save meerkat data in "data" folder
save(meerkats, file = file.path(here::here(), "data", "meerkats.RData"))As you see above, I am reading it, renaming some variables to make it look prettier and easier to handle when running stats on it and finally I am saving it in the \data folder, which I’ll talk about next:
\data
The \data folder will contain the actual data you will use in your scripts (in .RData format) and will be available to you immediately after you load your R package. As an example, I can take a look at the meerkats data without having to load anything because it is saved in the data folder!
head(meerkats)## obs_feeds obs_hours r_2_brood group_id brood_id delta_mass
## 1 0 11.1 0.25 bfb_c_sfi bfb0802 -0.03
## 2 0 11.2 0.25 bfb_c_sfi bfb0802 0.28
## 3 0 12.8 0.25 bfb_c_sfi bfb0802 -0.08
## 4 3 12.6 0.25 bfb_c_sfi bfb0802 0.31
## 5 16 12.2 0.25 bfb_c_sfi bfb0802 0.17
## 6 12 11.5 0.25 bfb_c_sfi bfb0802 0.14Where did you find all this?
Everything I have explained is extracted from the book “R packages” by the most awesome Hadley Wickham, the head developer for Rstudio and co-author of packages as awesome as tidyverse, ggplot2, pkgdown etc. The book is absolutely free and you can find it here: https://r-pkgs.org/. It has soo many more awesome things I did not develop here! Feel free to check it out!
